
Do Not Leave a Gap: Hallucination-Free Object Concealment in Vision-Language Models
Published in ECCV, 2026
Links
- Paper: arXiv
Key Idea
Hallucination is not caused by removing objects — it is caused by breaking representational continuity.
Motivation: Why Do Object-Hiding Attacks Cause Hallucination?
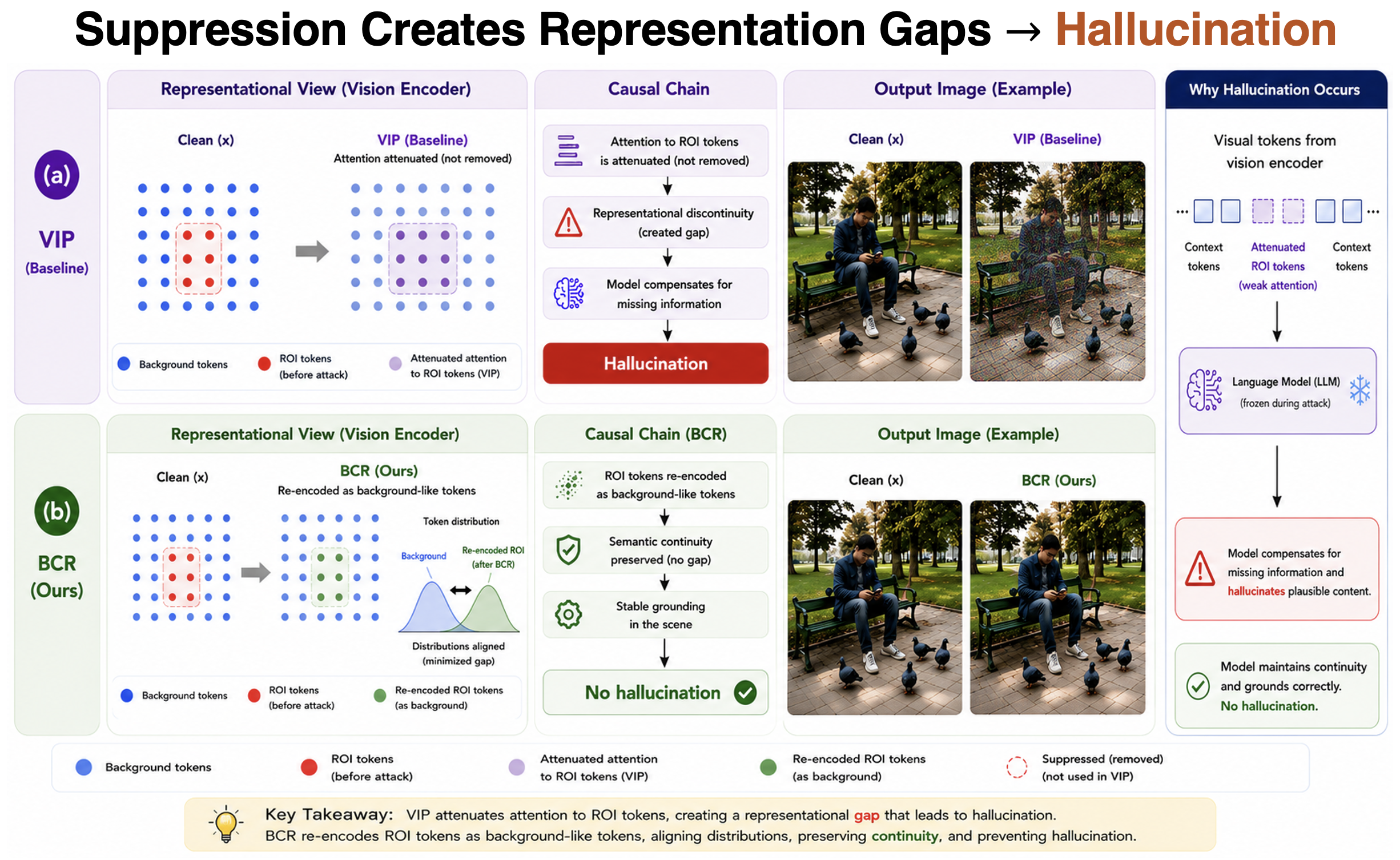
Suppression-based object concealment methods remove or weaken region-specific representations.
This creates gaps in representation space, forcing the model to “fill in” missing information and often resulting in hallucinated objects.

Insight: Continuity Prevents Hallucination
Hallucination emerges when representation continuity is broken, not simply when objects are absent.
If representations remain statistically and semantically consistent with the surrounding context, the model maintains coherent reasoning and avoids inventing objects.
Method: Background-Consistent Re-encoding (BCR)
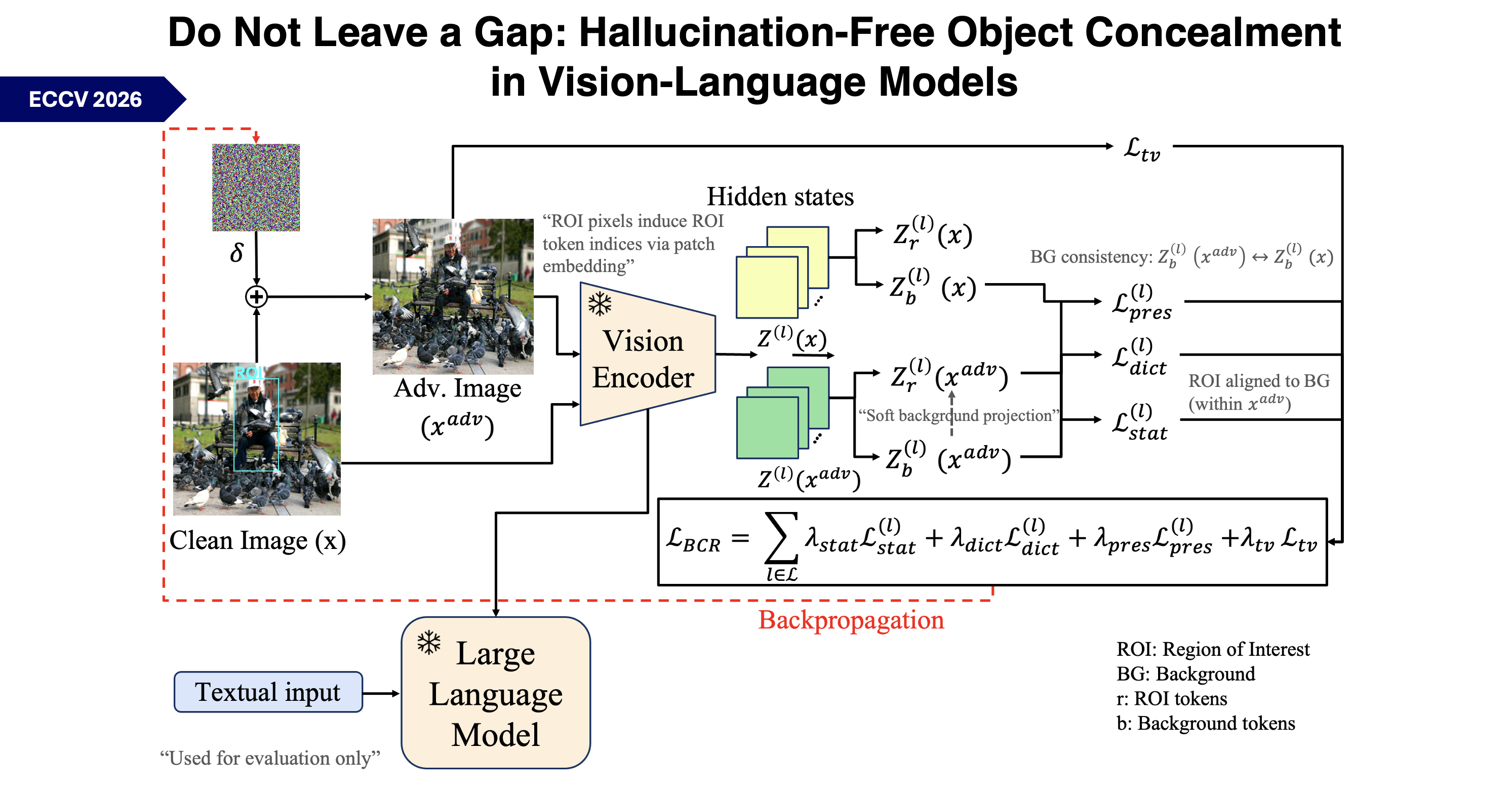
We propose Background-Consistent Re-encoding (BCR), a new paradigm for object concealment.
BCR re-encodes target object representations to match the statistical and semantic distribution of the background, while preserving:
- token structure
- attention flow
- global scene semantics
This prevents the representational gaps that trigger hallucination.
Positioning
Unlike suppression-based approaches that introduce semantic discontinuities, BCR preserves representational structure while modifying content.
This reframes object concealment from removal to distributional alignment, enabling hallucination-free manipulation.
Abstract
Vision-language models (VLMs) exhibit strong multimodal reasoning capabilities but remain vulnerable to adversarial manipulation of visual content.
Existing object-hiding methods primarily rely on suppressing or removing region-specific representations, often introducing semantic discontinuities that lead to hallucination, where models generate plausible but incorrect objects.
We show that hallucination arises not from object absence, but from disruptions in representational continuity.
To address this, we propose Background-Consistent Re-encoding (BCR), a new class of object concealment attacks that hide target objects by aligning their representations with the statistical and semantic distribution of surrounding background regions.
Our method preserves token structure and attention flow, preventing the representational gaps that trigger hallucination.
We introduce a pixel-level optimization framework that enforces background-consistent representations across multiple transformer layers while maintaining global scene coherence.
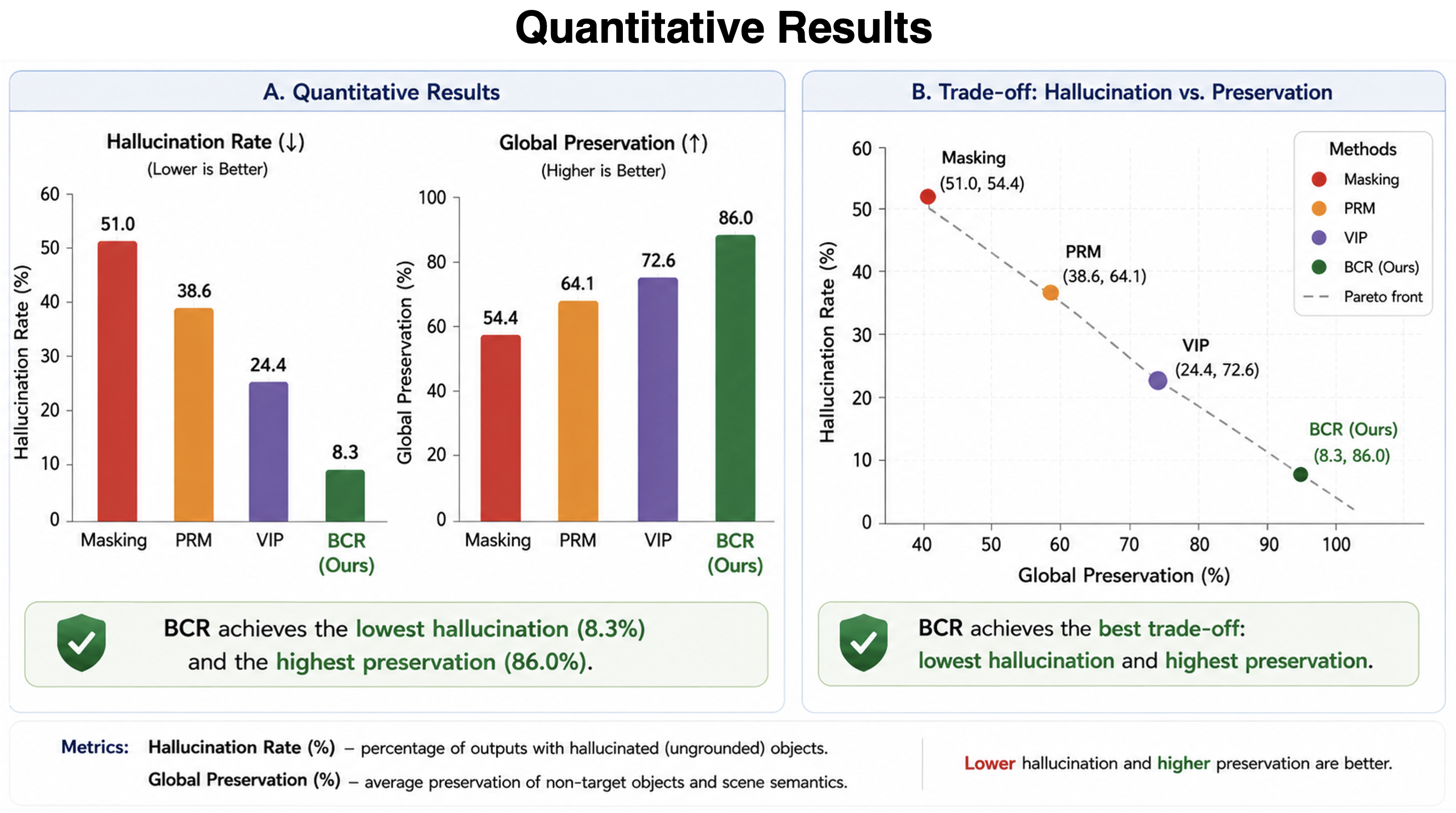
Extensive experiments on state-of-the-art VLMs demonstrate that BCR effectively conceals target objects while preserving up to 86% of non-target objects and reducing grounded hallucination by up to 3× compared to suppression-based baselines.
Qualitative results confirm that BCR maintains semantic consistency without introducing spurious objects.
Our findings establish representational continuity as a key factor in hallucination behavior and open a new direction for adversarial analysis in multimodal systems.
Key Contributions
- We show that hallucination is driven by representational discontinuity, not object absence.
- We introduce Background-Consistent Re-encoding (BCR), a novel object concealment paradigm.
- We design a pixel-level optimization framework enforcing background-consistent representations across multiple transformer layers.
- We demonstrate significant hallucination reduction while preserving non-target objects across multiple VLMs.
Results: Concealment Without Hallucination
BCR hides target objects while preserving global scene coherence and significantly reducing hallucination compared to suppression-based approaches.

Broader Perspective: Beyond Object Concealment
BCR introduces a broader perspective on hallucination in multimodal systems:
hallucination is fundamentally linked to representational discontinuity.
While prior approaches primarily focus on suppressing or removing visual evidence, our findings suggest that multimodal models rely heavily on the continuity and consistency of intermediate representations to maintain coherent reasoning.
This perspective has implications beyond adversarial object concealment, including:
Hallucination mitigation in VLMs
Preserving representational continuity may help reduce spurious generations and grounded hallucinations in multimodal reasoning systems.Privacy-preserving visual manipulation
Concealment can be achieved without introducing obvious artifacts or semantic inconsistencies.Robust multimodal alignment
Understanding how continuity affects cross-modal reasoning may improve the reliability of future vision-language systems.Adversarial analysis of generative AI
BCR highlights continuity as a new axis for studying vulnerabilities in multimodal foundation models.
More broadly, this work suggests that robustness and reliability in multimodal AI may depend not only on what information is removed, but on how representations evolve and remain connected throughout the model.
Citation
@misc{guesmi2026leavegaphallucinationfreeobject,
title={Do Not Leave a Gap: Hallucination-Free Object Concealment in Vision-Language Models},
author={Amira Guesmi and Muhammad Shafique},
year={2026},
eprint={2603.15940},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2603.15940},
}